Cobb County Building & Fire Code Agentic RAG Assistant
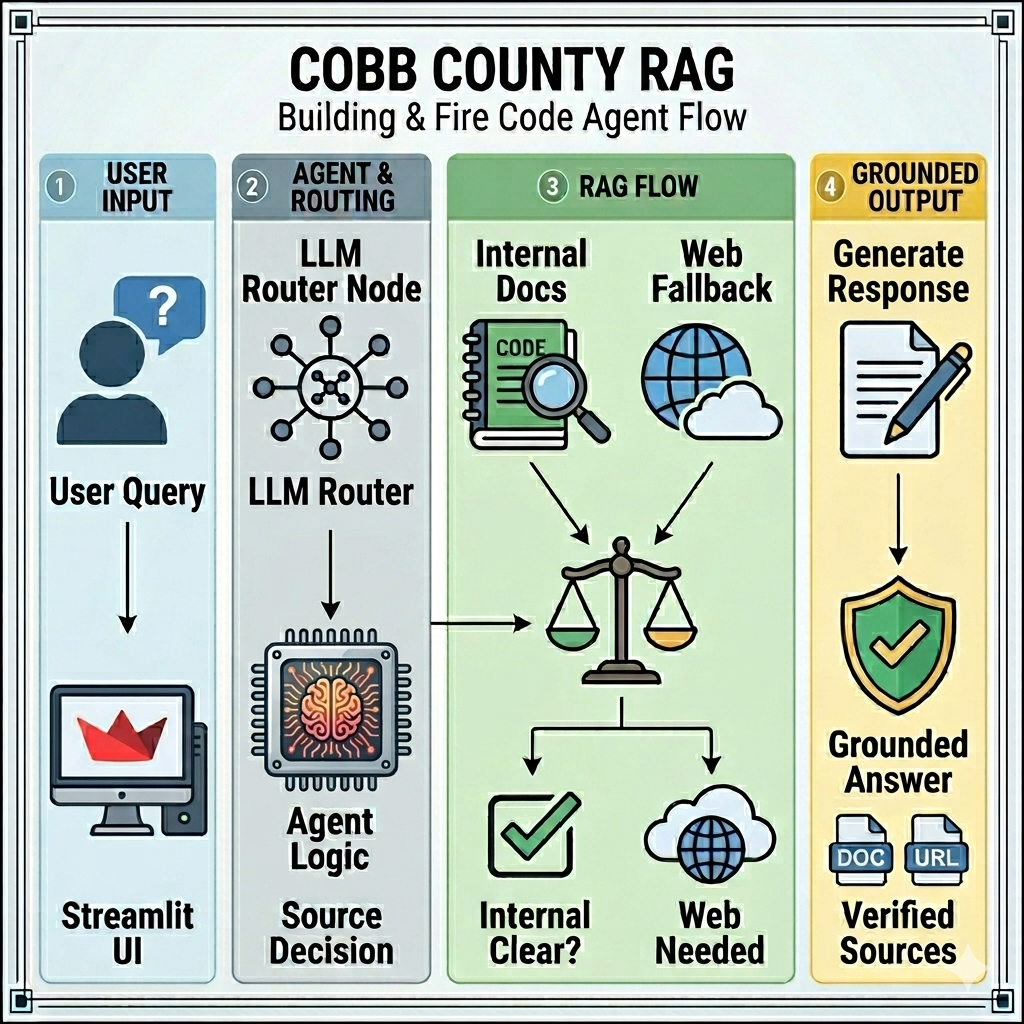
This project is an agentic retrieval-augmented generation (RAG) application for Cobb County, Georgia building and fire code questions. It uses local PDF documents as the primary knowledge base, supports four retrieval configurations, and falls back to official web sources when local evidence is weak or when a question asks about current, adopted, recently changed, or effective-date information.
The system demonstrates production-minded RAG engineering: document ingestion, selectable retrieval backends, vector and hybrid search, LLM routing, deterministic context expansion, strict evidence gating, source-grounded synthesis, web verification, LangSmith evaluation, Docker support, and a recruiter-friendly Streamlit interface.
Background & Problem Statement
Building and fire code information is difficult to search because it is spread across ordinances, code PDFs, county forms, permit guidance, plan-review checklists, Fire Marshal documents, and state-level code references. A homeowner, contractor, reviewer, or administrative user may know the question they want to ask, but not the exact document, section, or page where the answer appears.
Problem Statement: Can a deployable RAG assistant help users ask natural-language questions about Cobb County code and permitting documents while keeping answers grounded in cited local documents and current web evidence when verification is needed?
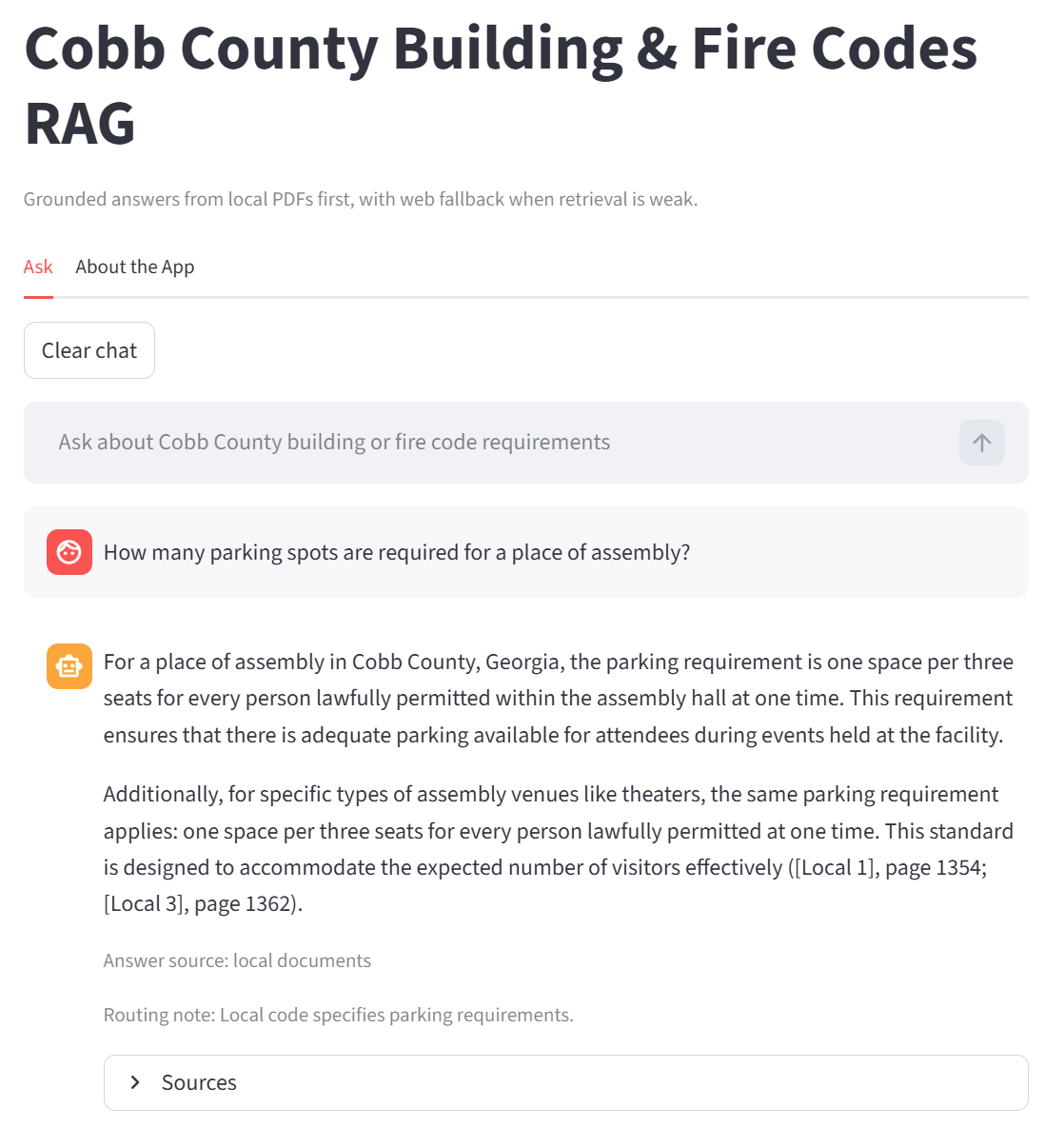
Streamlit Chat Interface
The front end is a Streamlit chat application designed for portfolio review and technical inspection. Users submit a code or permitting question, then receive a concise answer with source references and an answer-source label. The Settings & Eval dashboard lets users switch between all four retrieval options and view cached LangSmith evaluation metrics without restarting the app.
Document Corpus & Data Policy
The local corpus is designed around Cobb County, Georgia building and fire code research. It includes county ordinance PDFs, Fire Marshal forms and checklists, building permit and tenant build-out guidance, fire inspection documents, hydrant and sprinkler resources, emergency equipment guidance, and Georgia code references.
- Local PDFs used during development: 41 files.
- Raw PDF size: approximately 60 MB.
- Loaded pages: 4,093+ pages.
- Vector chunks: 13,844 chunks stored in Chroma.
- Repository policy: raw PDFs are excluded, while the generated vectorstore and BM25 artifacts are tracked with Git LFS for deployment.
Supported Retrieval Backends
| Backend | UI Label | Retrieval Strategy |
|---|---|---|
cobb_code_docs_original |
Option 1: PyPDF + Chromadb | Original PyPDF/LangChain page extraction with Chroma vector search |
cobb_code_docs_docling |
Option 2: Docling + Chromadb | Docling layout-aware Markdown conversion with Chroma vector search |
docling_chroma_bm25_hybrid |
Option 3: Docling + Chroma + BM25 Hybrid Search | Docling chunks searched with both Chroma vector retrieval and a persisted local BM25 keyword corpus |
docling_chroma_bm25_expansion |
Option 4: Docling + Query Expansion + BM25 Hybrid Search | Reuses Option 3 indexes, expands the original question into five retrieval queries, deduplicates results, and fuses rankings |
Agentic RAG Architecture
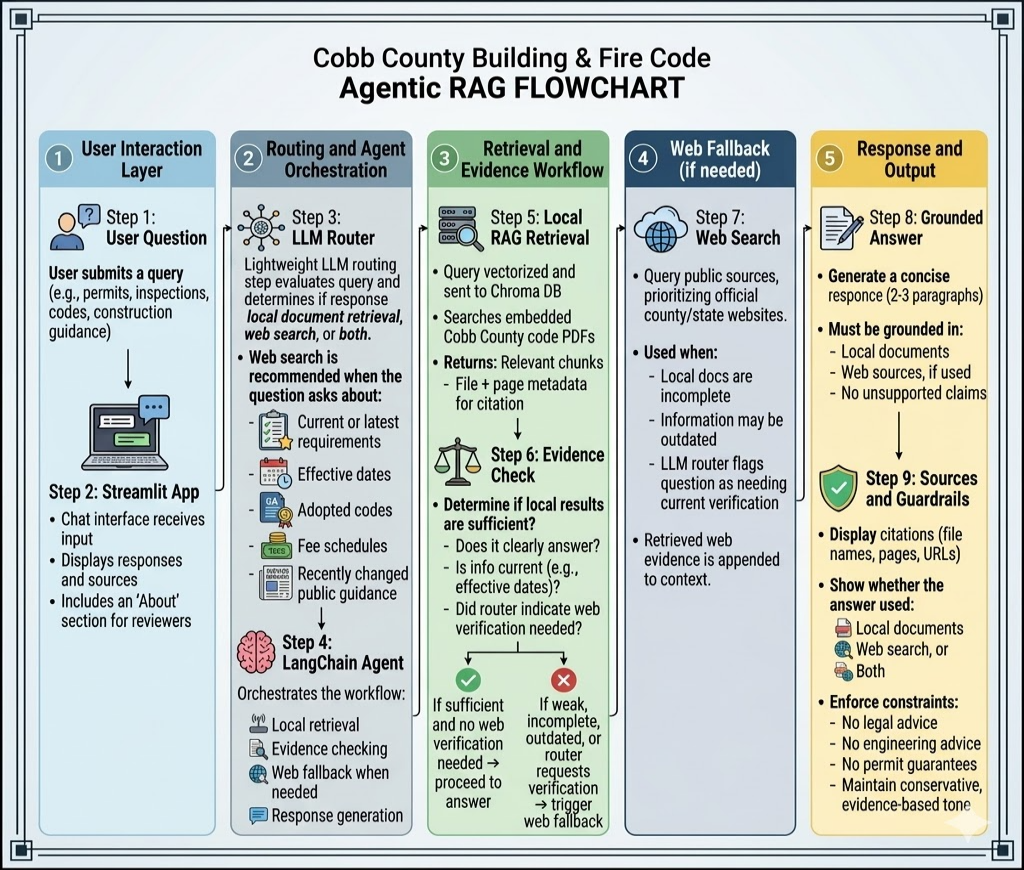
The app uses an agentic RAG workflow rather than a single prompt-only LLM call. A lightweight LLM router evaluates the question, the selected retrieval backend searches local evidence, deterministic neighbor expansion keeps nearby checklist items visible, an evidence check determines whether the local context is sufficient, and web search is triggered when current-code verification or weak local evidence requires it.
- Settings selector: switches new questions across four retrieval configurations without requiring an app restart.
- Query routing: flags whether the question needs local documents, web search, or both.
- Local retrieval: uses Chroma vector search or Chroma + BM25 hybrid retrieval depending on the selected option.
- Query expansion: Option 4 uses one LLM call to create four additional retrieval queries before hybrid retrieval.
- Deterministic context expansion: expands each retrieved chunk with same-document neighboring chunks
chunk_index - 1andchunk_index + 1. - Strict evidence gate: requires exact supporting evidence for numeric, code, inspection, permit, and procedural answers.
- Web fallback: prioritizes public county and state web sources for current-code verification.
Retrieval Engineering
This project does not train a conventional tabular ML model. Instead, the engineering work focuses on building reliable retrieval over long, heterogeneous PDF documents where exact numbers, section references, conditions, and procedural language matter. The final app compares vector-only retrieval against local hybrid retrieval and query-expansion retrieval.
- Original parsing: preserves the initial PyPDF/LangChain page extraction pipeline.
- Docling parsing: converts layout-aware PDF content to Markdown before chunking, which can help with headings, tables, sections, and multi-column documents.
- BM25 hybrid retrieval: combines keyword matching with dense vector retrieval using Reciprocal Rank Fusion.
- Query expansion: generates four additional technical and step-back queries, retrieves with all five queries, deduplicates, and fuses rankings.
- Context expansion: retrieves small chunks for search quality, then expands each hit with only same-document neighboring chunks before adequacy checking.
- Metadata tracking: file name, source path, parser type, backend, chunk index, section, and page range are retained where available.
- Evidence thresholding: weak retrieval or current-code language can trigger web search or conservative abstention.
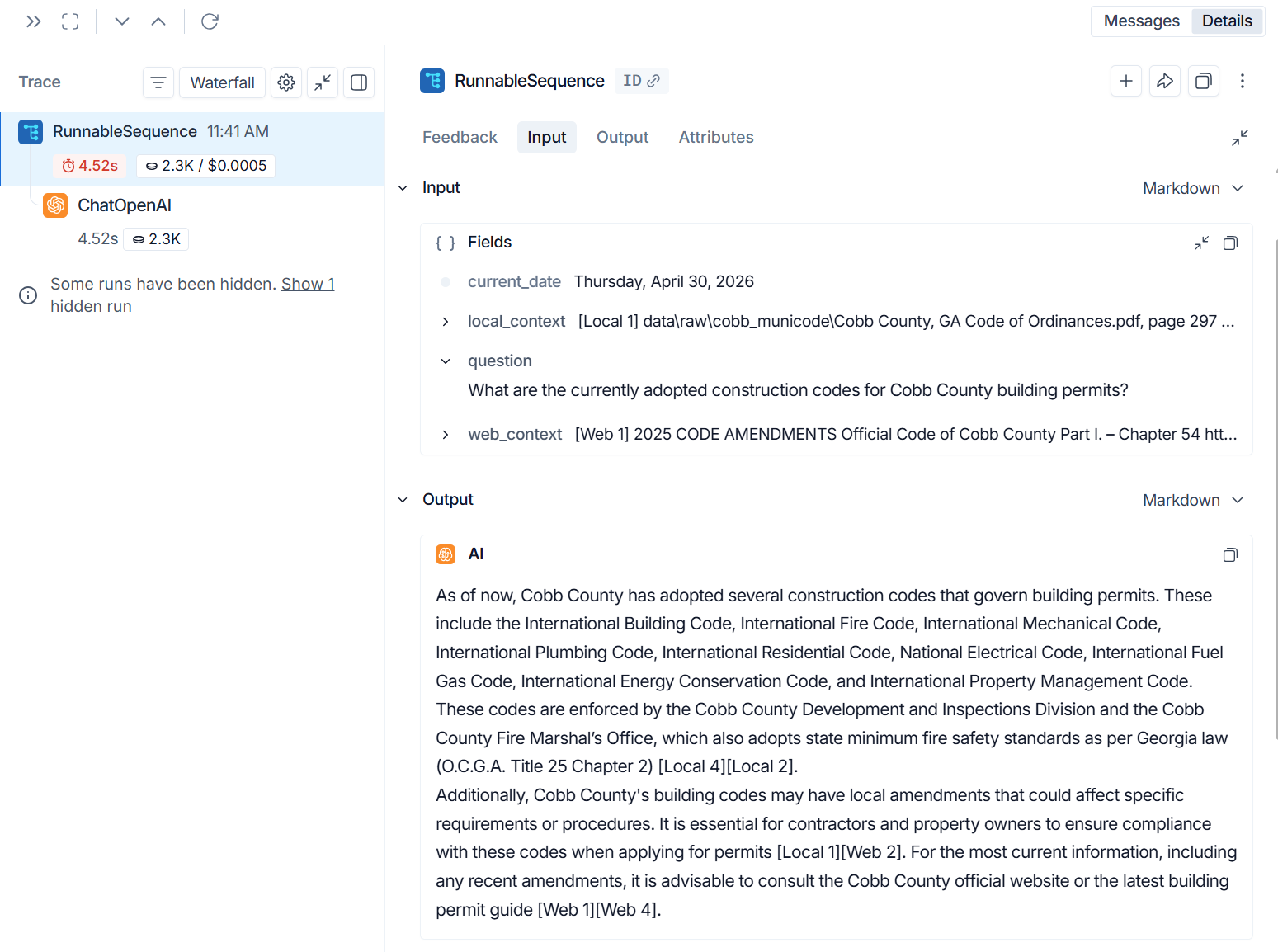
LangSmith Tracing, Evaluation & Validation
LangSmith traces were used to inspect the full chain input, routing context, local PDF evidence, web-search evidence, token usage, latency, and final answers. The project uses a fixed 50-question golden evaluation set and cached LangSmith experiment scores for faithfulness, answer relevance, context precision, context recall, and latency.
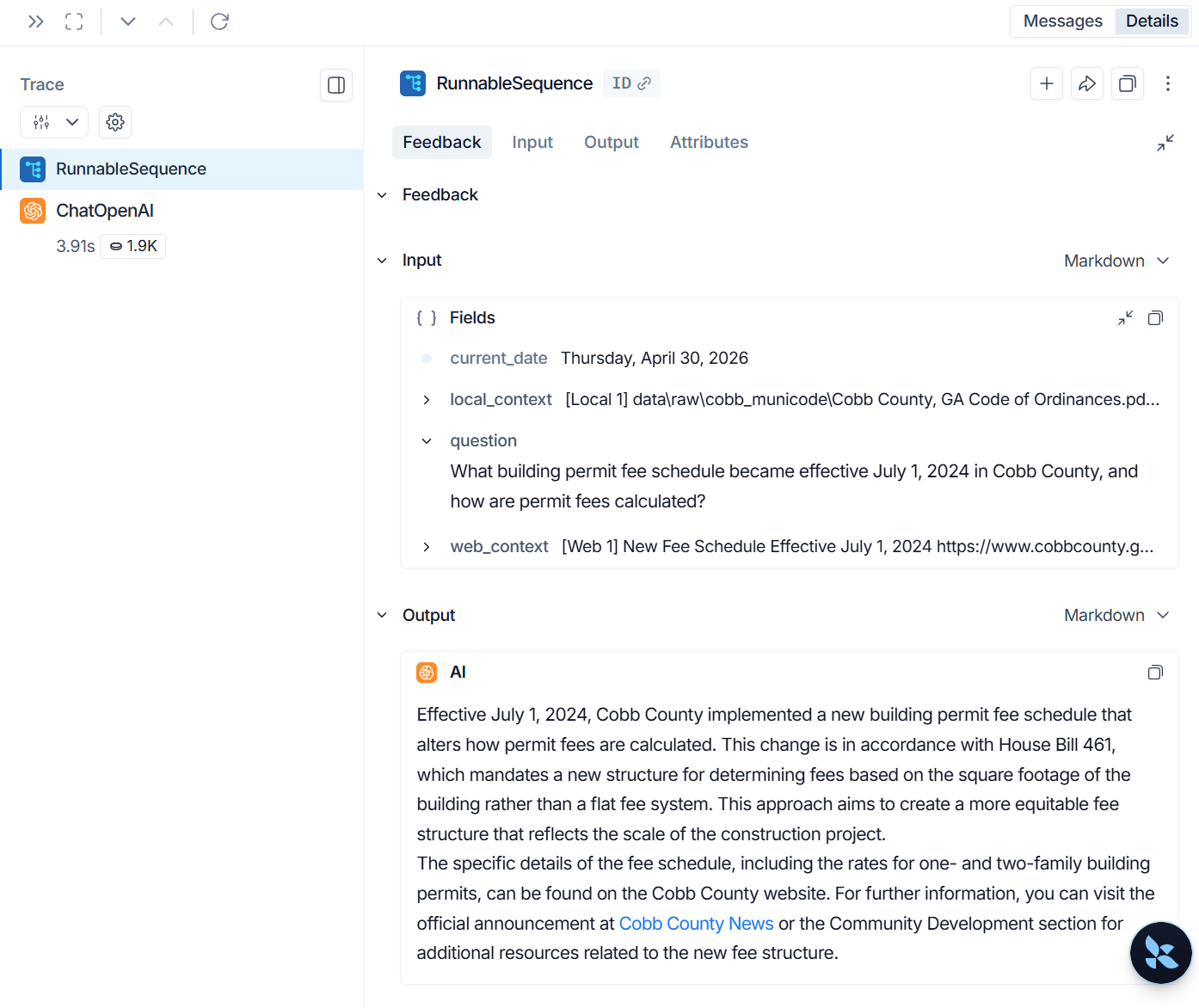
Evaluation Methodology
The Settings & Eval dashboard compares all four retrieval configurations using the same fixed 50-question
golden dataset. Metrics are persisted under eval_results/ so the dashboard can load results immediately
without automatically launching a new evaluation run.
- Faithfulness: whether all answer claims are supported solely by the retrieved context.
- Answer relevance: whether the generated response directly answers the user's question.
- Context precision: whether retrieved context is useful and well-ranked rather than noisy.
- Context recall: whether the retrieved context contains the necessary facts compared with the ground-truth answer.
- Latency: mean, P50, and P99 runtime in seconds across the fixed evaluation set.
Results & System Checks
The project was validated through ingestion checks, retrieval smoke tests, current-code routing tests, web search fallback tests, syntax checks, Docker support, manual review of representative questions, and LangSmith evaluation across four retrieval options.
Retrieval Method Performance Comparison
| Option | Method | Answer Relevance | Context Precision | Context Recall | Faithfulness | Avg Latency (s) | P50 (s) | P99 (s) |
|---|---|---|---|---|---|---|---|---|
| 1 | PyPDF + Chromadb | 0.695 | 0.695 | 0.610 | 0.940 | 15.3 | 10.4 | 108.8 |
| 2 | Docling + Chromadb | 0.625 | 0.650 | 0.615 | 0.930 | 13.6 | 12.2 | 36.1 |
| 3 | Docling + Chroma + BM25 Hybrid Search | 0.725 | 0.765 | 0.720 | 0.955 | 15.4 | 11.4 | 69.0 |
| 4 | Docling + Query Expansion + BM25 Hybrid Search | 0.730 | 0.755 | 0.645 | 0.965 | 23.4 | 21.3 | 50.2 |
Best balanced configuration: Option 3 is the strongest practical default because it produces the best context precision and context recall while avoiding the extra query-expansion latency of Option 4. Highest faithfulness: Option 4 reaches the top faithfulness score, but the added query-expansion LLM call increases median latency and does not improve context recall over Option 3.
Validation Summary
| Test Area | Result | Notes |
|---|---|---|
| PDF ingestion | Passed | Loaded Cobb County and Georgia code PDFs |
| Vector index build | Passed | Indexed 13,844 chunks into Chroma |
| Docling-enhanced indexing | Added | Builds cobb_code_docs_docling from Docling Markdown output |
| BM25 hybrid retrieval | Added | Persists a local BM25 corpus and fuses keyword and vector rankings |
| Query expansion retrieval | Added | Creates five total retrieval queries before hybrid ranking |
| Deterministic context expansion | Added | Expands retrieved chunks with same-document -1/+1 neighbors before evidence checks |
| Strict evidence gate | Added | Requires exact support before numeric, code, inspection, permit, or procedural answers |
| LangSmith evaluation cache | Added | Saves per-backend metrics under eval_results/ |
| Web fallback | Passed | SerpAPI Google Search works from the app environment |
| Deployment support | Included | Streamlit Community Cloud, Dockerfile, and docker-compose.yml |
Key Insights
- Hybrid retrieval mattered most: Docling alone did not outperform the PyPDF baseline, but Docling paired with BM25 improved context precision and recall.
- Faithfulness improved through stricter evidence gating: the app refuses numeric, code, permit, inspection, and procedural answers unless exact support is visible in the supplied context.
- Neighbor expansion reduced false refusals: adding same-document neighboring chunks helps when a retrieved chunk lands just before an answer-bearing checklist item or table row.
- Query expansion has a cost: Option 4 produced the highest faithfulness and answer relevance, but at a substantially higher median latency.
- Recommended demo configuration: Option 3 gives the best retrieval-quality tradeoff for portfolio demonstrations.
Applied ML Engineering Value
This project demonstrates how modern LLM systems can be adapted to document-heavy public-sector workflows where answers must be grounded, current, and easy to verify. It is especially relevant to customer-facing AI platforms, conversational question answering, search and retrieval, agent workflows, and intelligent automation.
- RAG system design: combines selectable retrieval backends, local retrieval, hybrid search, routing, evidence checking, and web fallback.
- Operational grounding: returns source references instead of unsupported open-ended answers.
- Production mindset: includes reproducible ingestion, Docker support, environment templates, Git LFS artifacts, and hosted app deployment.
- Evaluation and observability: uses LangSmith traces and fixed golden-set metrics to inspect retrieval quality, routing decisions, latency, and generated outputs.
Databricks Implementation
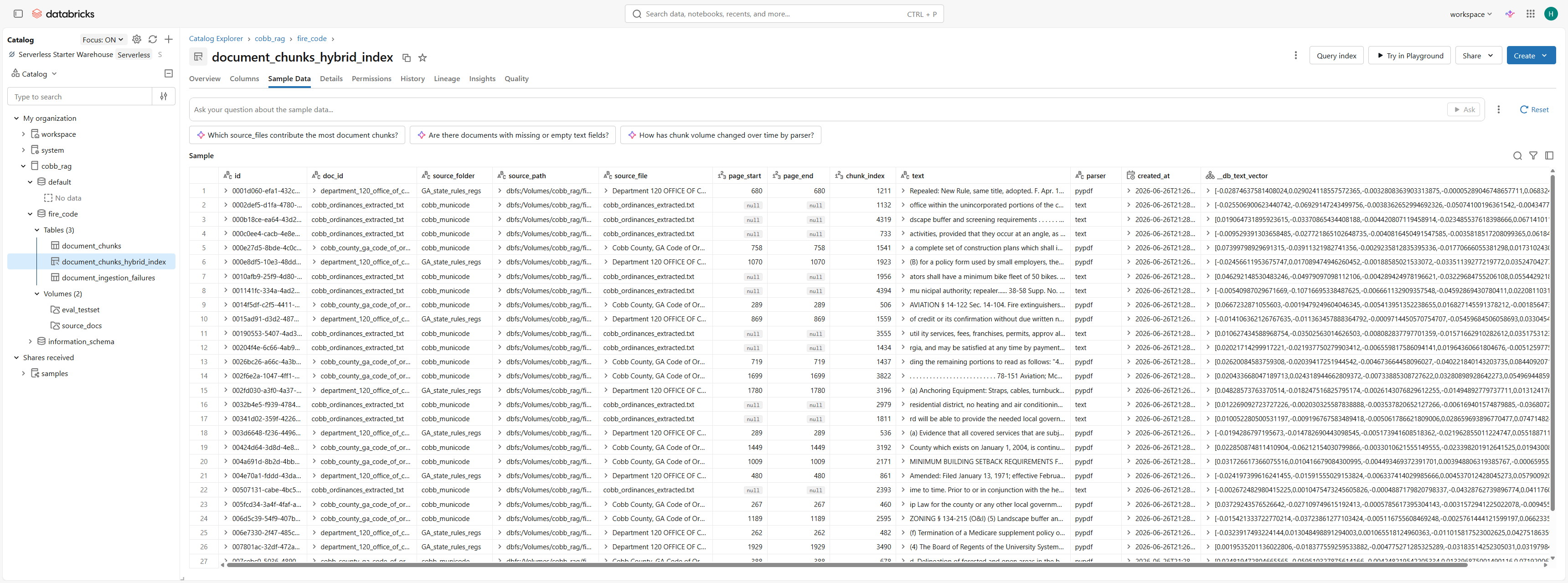
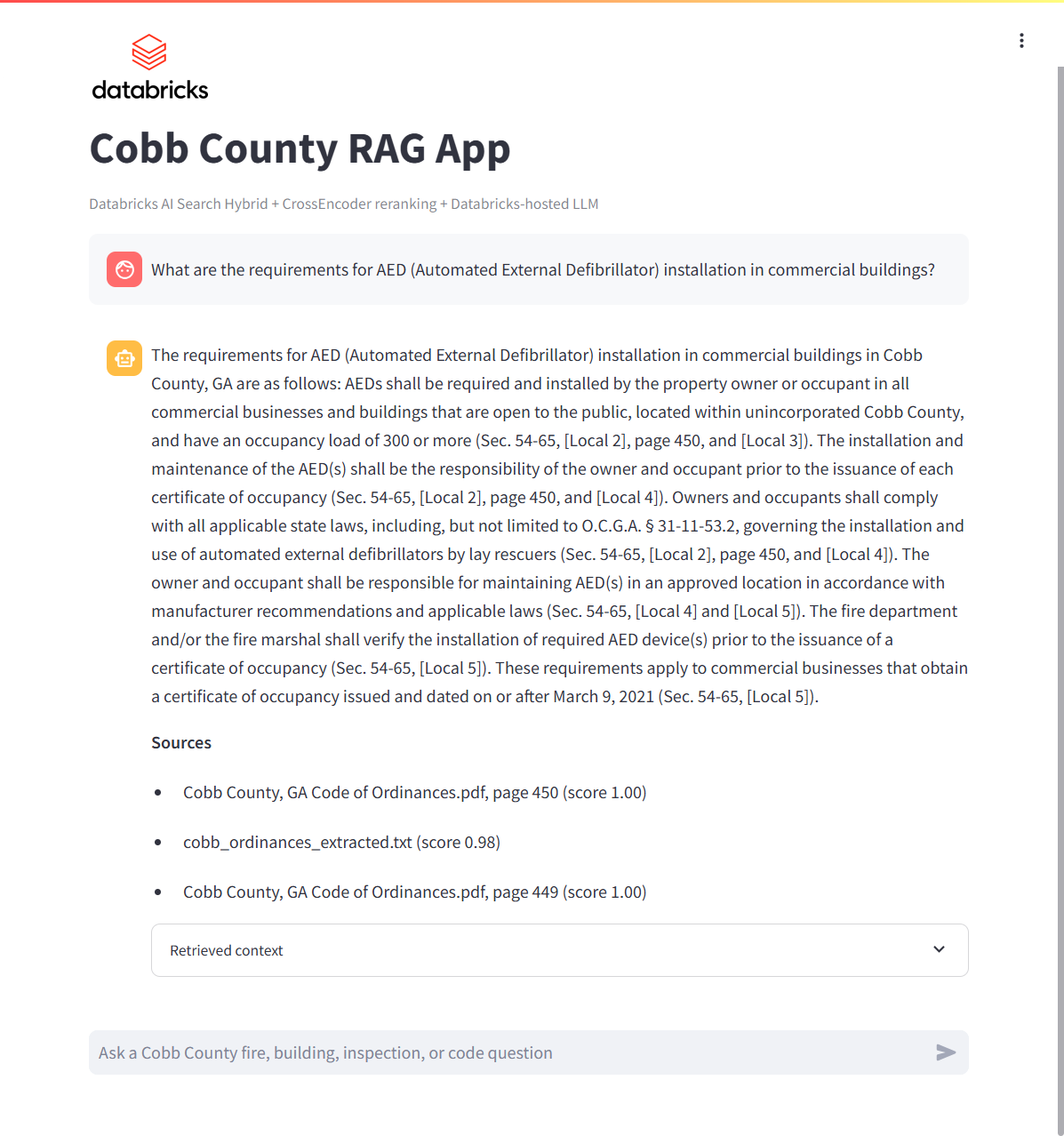
I also implemented a Databricks version of the app, adapting the local RAG workflow to a managed lakehouse deployment. Source documents are loaded from a Unity Catalog volume, chunked into a managed Delta table, indexed through Databricks AI Search hybrid retrieval, and served through a Databricks Streamlit app.
The Databricks pipeline preserves the important production behaviors from the original app where practical: hybrid document retrieval, same-document neighbor context expansion, CrossEncoder reranking, source-grounded answer generation, and evaluation against the same fixed 50-question golden test set.
- Lakehouse storage: documents and generated chunks are organized in Unity Catalog assets for governed retrieval workflows.
- Managed search: the local Chroma/BM25 layer is replaced with a Databricks AI Search hybrid index over the chunk table.
- Deployment target: the Streamlit interface is packaged as a Databricks app for workspace-hosted querying.
- Evaluation parity: Databricks RAG evaluation is performed using the same 50-question benchmark.
Databricks Evaluation Performance
| Setting | Questions | Faithfulness | Answer Relevance | Context Precision | Context Recall | Avg Latency (s) | P50 (s) | P99 (s) |
|---|---|---|---|---|---|---|---|---|
| Databricks AI Search Hybrid + CrossEncoder | 50 | 0.920 | 0.880 | 0.875 | 0.855 | 9.69 | 8.92 | 24.67 |
The Databricks deployment maintained strong grounding and retrieval quality while moving storage, indexing, and serving into managed platform services. Average latency was 9.69 seconds, with 8.92 seconds at P50 and 24.67 seconds at P99, reflecting the managed app and model-serving path plus occasional heavier retrieval or generation cases.
GitHub Repository & Live Demo
The full implementation and hosted Streamlit demo are available through the links below.
🔗 View Project Repository on GitHub
The repository includes the Streamlit app, LangChain agent workflow, Chroma retriever, BM25 hybrid retrieval, query expansion retrieval, PyPDF and Docling ingestion scripts, deterministic context expansion, LangSmith evaluation workflow, Docker files, environment template, and documentation for rebuilding local vector and BM25 indexes.
Disclaimer: this is a portfolio demonstration and educational project. It is not legal, engineering, building code, fire code, or permitting advice. Users should verify requirements directly with Cobb County, the Georgia Department of Community Affairs, the State Fire Marshal, and the authority having jurisdiction.