Multi-Agent GenAI System for Automated Hydrology Literature Review (CrewAI + LLMs)

This project built a multi-agent GenAI system that automates large portions of the hydrology literature review process. Instead of manually searching databases, downloading papers, and synthesizing findings, a coordinated set of AI agents handles topic scoping, document retrieval, summarization, and synthesis into researcher-ready reports.
Using CrewAI as the orchestration layer and modern LLMs (GPT / Gemini) as the reasoning engine, the system can take a high-level research question—such as climate change impacts on low flows or remote sensing–based flood mapping—and produce a structured, cited overview within hours, rather than days.
Background & Problem Statement
Hydrology and water-resources research often begins with a time-consuming literature review: identifying relevant papers, sorting through overlapping topics, and extracting key methods and findings. For complex topics—like climate-driven changes in extremes, remote sensing of water quality, or machine-learning applications in hydrology—this can take 3–7 days of focused effort.
Recent advances in GenAI, multi-agent frameworks, and retrieval-augmented generation present an opportunity to offload much of this mechanical work to AI systems, while keeping the human expert in control of interpretation and final judgment.
Problem Statement: How can we design a multi-agent GenAI workflow that automates the most repetitive parts of hydrology literature review—search, filtering, summarization, and basic synthesis—without sacrificing transparency or introducing hallucinated citations?
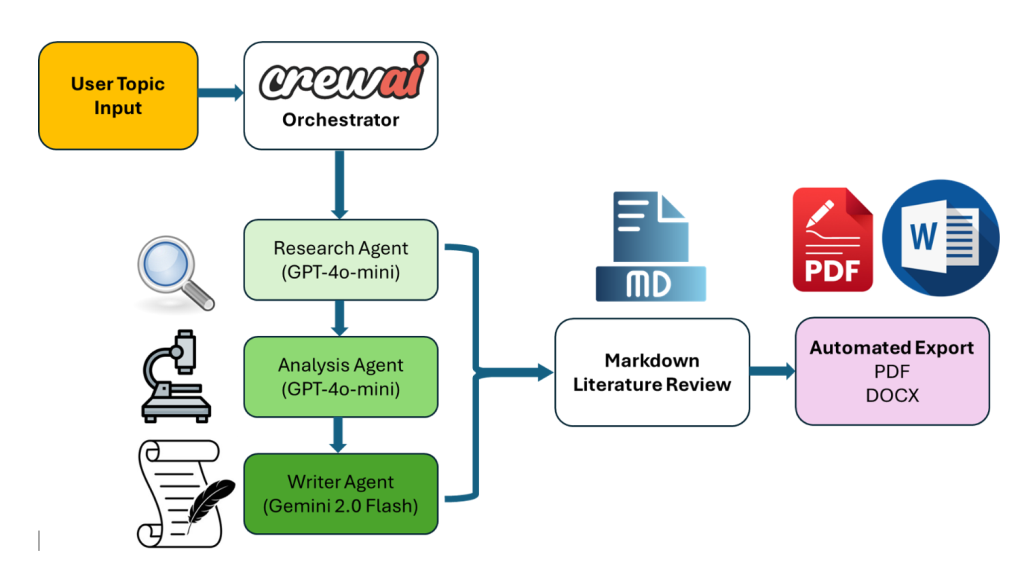
System Design & Agent Architecture
The system is organized around a crew of specialized agents, each with a clear role and shared context. CrewAI handles coordination, task delegation, and passing of intermediate artifacts between agents.
- Input Prompt Template: The user provides a research topic (e.g., “machine learning for flood forecasting in data-scarce basins”) plus optional constraints (time window, geographic region, key methods).
- Research Planner Agent: Interprets the query, decomposes it into sub-topics (datasets, methods, hydrologic variables, study regions), and drafts a search strategy for downstream agents.
- Search & Retrieval Agent: Uses web search and/or API calls to pull candidate papers from sources like Google Scholar, open repositories, and institutional pages, capturing titles, abstracts, URLs, and metadata into a structured format.
- Relevance Filter Agent: Evaluates each candidate against the topic and constraints, discarding off-topic or low-relevance papers and prioritizing high-signal sources (e.g., peer-reviewed articles, major conference papers, review articles).
- Summarizer Agent: Reads abstracts (and, where available, full-text excerpts) to produce concise structured summaries, including objective, methods, data, study region, and key findings.
- Synthesis & Gap-Analysis Agent: Aggregates individual summaries into a higher-level narrative: common approaches, prevailing results, disagreements, data/knowledge gaps, and potential directions for future work.
Workflow, RAG Integration & Output Generation
To keep the system grounded in real documents and reduce hallucinations, the agents operate on a combination of structured metadata and retrieved text passages.
- Document Store & RAG: Parsed abstracts and key text segments are stored in a lightweight vector index, allowing agents to retrieve relevant passages for each question they answer during summarization and synthesis.
- Citation Tracking: Each summary item is associated with explicit citation metadata (authors, year, title, link), and the Synthesis agent is instructed to reference these citations rather than invent new ones.
- Configurable Depth: Users can toggle between a “quick scan” mode (fewer papers, shorter summaries) and a “deep dive” mode (more sources, richer synthesis) depending on time constraints.
-
Output Formats:
The final product is rendered as a structured Markdown / HTML report,
including:
- Executive summary of the topic
- Bullet-point summaries of individual papers
- Methodological map (e.g., ML methods, hydrologic variables, basins)
- Identified gaps and potential research questions
- Human-in-the-Loop Editing: The report is intentionally concise and structured so the human researcher can quickly audit, adjust, and expand it into a full literature review or manuscript section.

Impact & Actionable Insights
While still a research tool rather than a fully productized platform, the multi-agent system demonstrates the tangible value of GenAI for domain scientists.
- Productivity Gains: Early tests indicate that the system can reduce a 3–7 day manual hydrology literature review to a same-day workflow, especially for scoping reviews and method scans.
- Better Coverage: By systematically exploring search results and filtering with explicit criteria, the system often surfaces relevant papers that might be overlooked in a quick manual search.
- Reusable Research Asset: The generated summaries and synthesis sections can be reused across proposals, reports, and manuscripts, creating a growing internal knowledge base over time.
- Extensibility: The same architecture can be adapted to other technical domains—climate science, water quality, remote sensing—by updating the agent instructions and retrieval sources.
- Showcase for GenAI Engineering: Highlights practical experience in multi-agent GenAI design, RAG, prompt engineering, and domain-specific evaluation—skills that transfer directly to modern AI/ML roles.